Abstract
Generalizing deep reinforcement learning agents to unseen environments remains a significant challenge. One promising solution is Unsupervised Environment Design (UED), a co-evolutionary framework in which a teacher adaptively generates tasks with high learning potential, while a student learns a robust policy from this evolving curriculum. Existing UED methods typically measure learning potential via regret, the gap between optimal and current performance, approximated solely by value-function loss. Building on these approaches, we introduce the transition prediction error as an additional term in our regret approximation. To capture how training on one task affects performance on others, we further propose a lightweight metric called co-learnability. By combining these two measures, we present Transition-aware Regret Approximation with Co-learnability for Environment Design (TRACED). Empirical evaluations show that TRACED yields curricula that improve zero-shot generalization across multiple benchmarks while requiring up to 2× fewer environment interactions than strong baselines. Ablation studies confirm that the transition prediction error drives rapid complexity ramp-up, and that co-learnability delivers additional gains when paired with the transition prediction error. These results demonstrate how refined regret approximation and explicit modeling of task relationships can be leveraged for sample-efficient curriculum design in UED.
Contributions
In this paper, we introduced Unsupervised Environment Design (UED) method with two key components:
- An explicit transition prediction error term for regret approximation.
- A lightweight Co-Learnability metric that captures cross-task transfer effects.
By integrating these into the standard generator-replay loop, TRACED produces curricula that escalate environment complexity in tandem with agent learning.
Zero-shot Generalization on MiniGrid
Performance Results
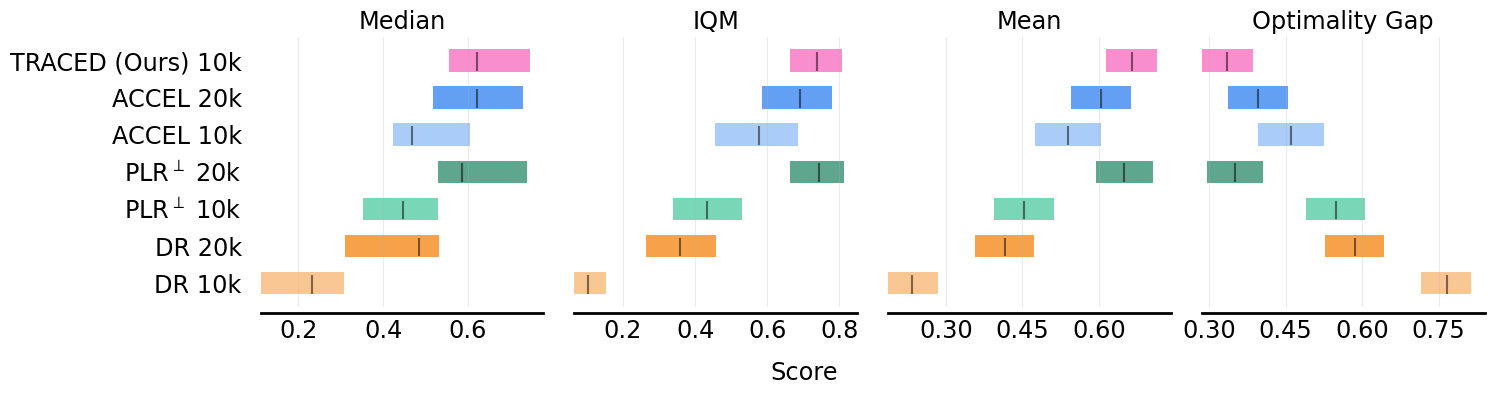
Zero-Shot Transfer Performance in MiniGrid
Agent Trajectory Visualizations on MiniGrid
Room Navigation
FourRooms-v0
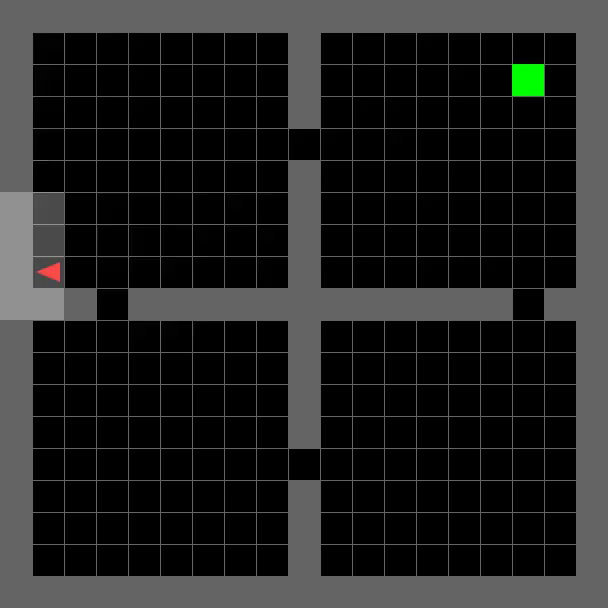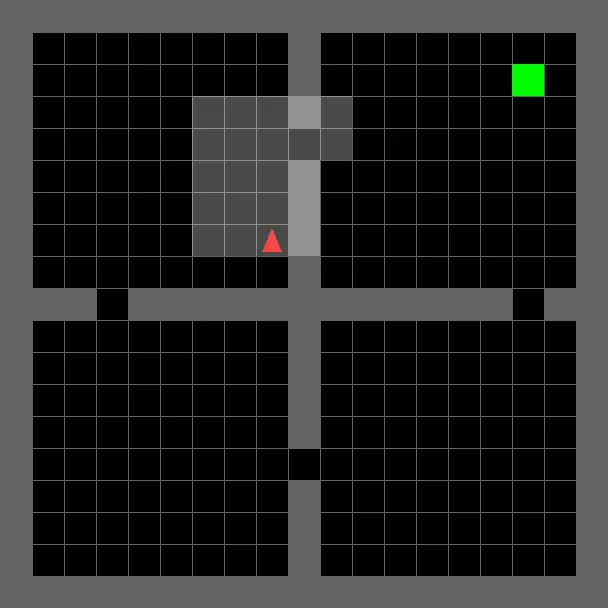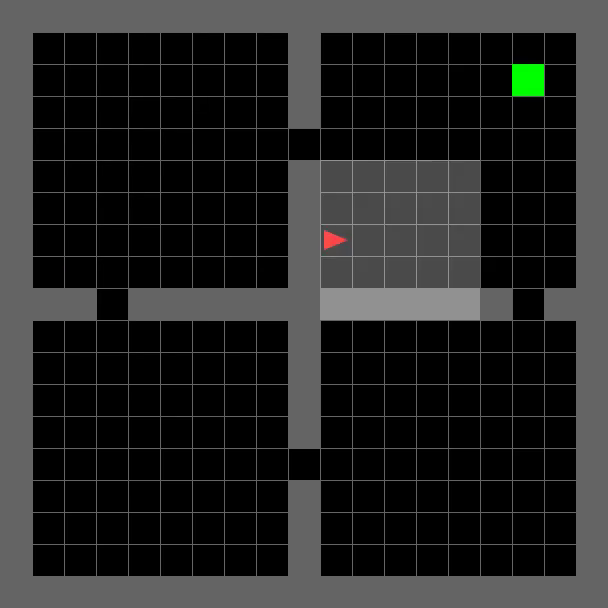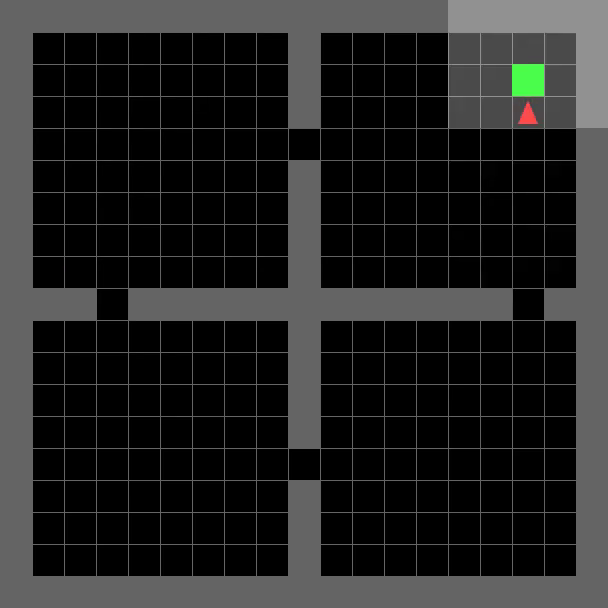
SixteenRooms-v0
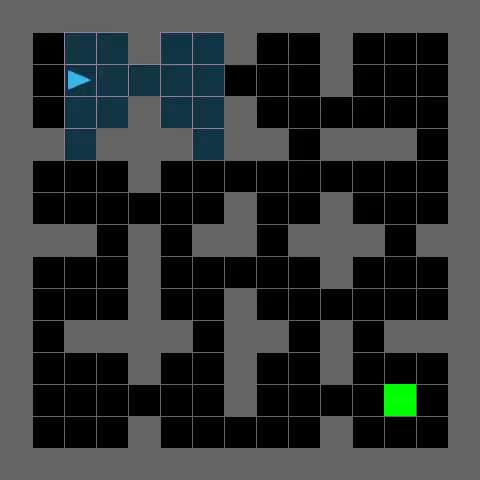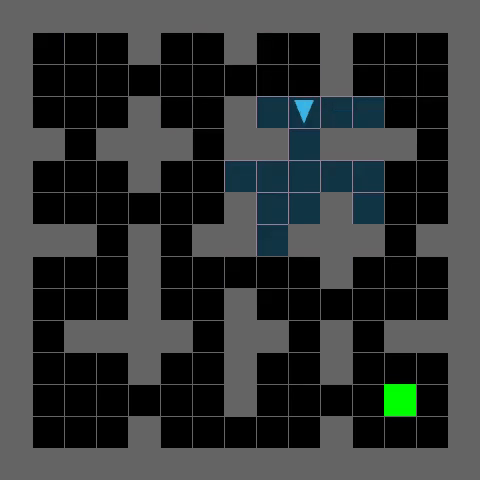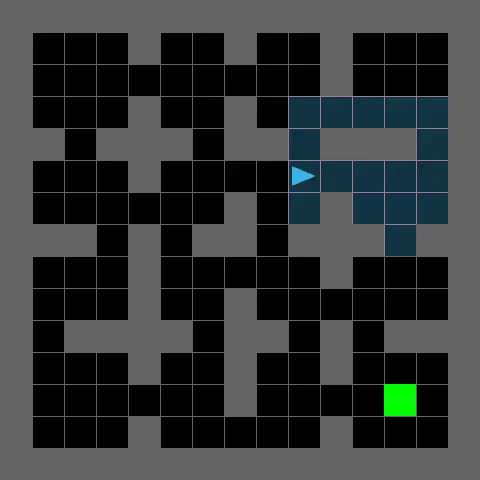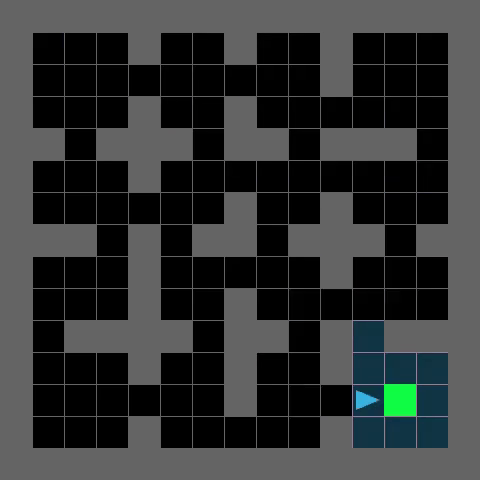
SixteenRoomsFewerDoors-v0

Corridor Navigation
SimpleCrossingS9N1-v0

SmallCorridor-v0

LargeCorridor-v0

Complex Maze Navigation
Labyrinth-v0

Labyrinth2-v0

PerfectMazeMedium-v0

Maze-v0

Maze2-v0

Maze3-v0

TRACED enables efficient path planning and robust generalization to challenging maze environments, as demonstrated by the agent's successful navigation to the goal (green).
Zero-shot Generalization on BipedalWalker
Performance Results
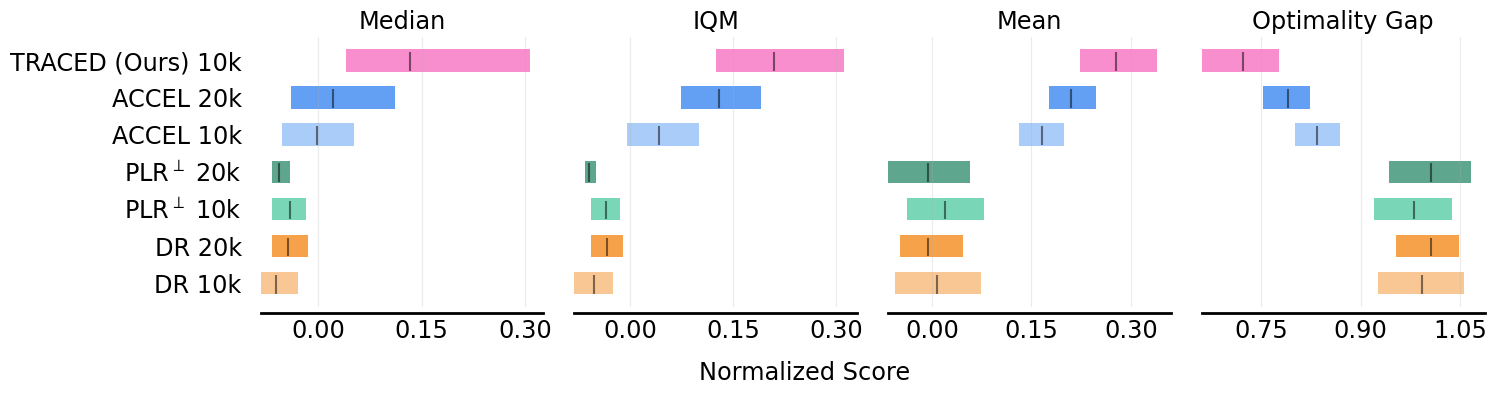
Aggregate zero-shot performance on six held-out BipedalWalker terrains
Agent Trajectory Visualizations on BipedalWalker
BipedalWalker-v3

Hardcore-v3

Roughness-v0

StumpHeight-v0

Stairs-v0

PitGap-v0

Illustrations of zero-shot rollouts in BipedalWalker environments. The agent dynamically modulates joint torques to ascend and descend steps, leap over gaps, step onto stumps, and maintain balance on uneven ground, confirming TRACED’s effectiveness in teaching transferrable locomotion skills.
Visualization of Level Evolution
MiniGrid

BipedalWalker

Left: The visualization of how the Minigrid environment evolves as the number of blocks increases. Each step of the evolutionary process produces an edited level that has a high learning efficiency.
Right: The visualization of the level evolving progression in the BipedalWalker environment. In this example, starting with plain terrain, the pits are created and their number increases, then the roughness increases, then stairs and stumps are created and their number, width, and height increase. This progress is automatically designed by our TRACED algorithm.